Why Private AI Belongs on a GPU
For years, the secure multi-party computation (MPC) community optimized for one thing above all: fewer rounds of communication. The logic was sound — the computations people studied were small, so the back-and-forth between parties dominated the cost. Shave a round, win.
FALCON asked a simple question: what happens when the computation gets big?
The reason it matters is mechanical. Multiplying two \(n \times n\) matrices is super-quadratic — strictly more than \(O(n^2)\) work. But the communication to do that multiplication privately stays quadratic, \(O(n^2)\): you exchange shares proportional to the matrix size, in a single round. So as the matrices grow, computation grows faster than communication — and past a crossover, it wins.
This isn’t just a back-of-the-envelope story; it shows up in the measurements. The figure below, from the paper, breaks down end-to-end private-inference cost (WAN, malicious setting) across networks of increasing size. On small MNIST networks, communication is ~94% of the cost. By VGG on Tiny ImageNet, that has flipped: computation is ~78%.
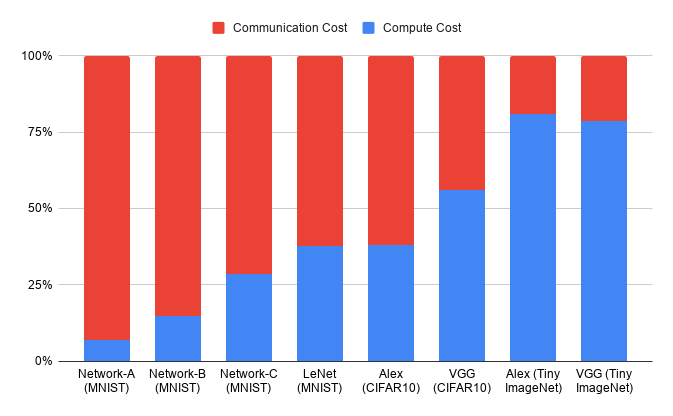
This runs against the conventional wisdom that MPC is communication-bound. Once you reach realistic network sizes, the bottleneck is arithmetic, not the network — and the moment your bottleneck is arithmetic, the prescription writes itself: move it onto a GPU.
So what does it look like to take that prescription seriously — to put private training on a GPU and run a network end to end? That’s the story of Piranha.